
Architecture
Overview
UmaDB is organized into a set of layered components that work together to provide a durable, concurrent, and queryable event store. Each layer has a clear responsibility, from client communication at the top to low-level file management at the bottom. Requests typically flow down the stack, from client calls through the API and core logic into the storage and persistence layers, while query results and acknowledgements flow back up the same path.
| Layer | Component | Responsibility |
|---|---|---|
| Client | gRPC Clients | Provides application-facing interfaces for reading and writing events |
| API | gRPC Server | Defines the public API surface (gRPC service) |
| Logic | UmaDB Core | Implements transaction logic, batching, and concurrency control |
| Storage | B+ Trees | Indexes events, tags, and free pages for efficient lookups |
| Persistence | Pager and File System | Durable paged file I/O |
Data Flow Summary
- Clients send read or write requests through gRPC interfaces.
- The API layer validates inputs and routes requests to the event store core.
- The Core Logic Layer applies transactional semantics, batching, and concurrency control.
- The Storage Layer organizes and indexes event data for fast tag and position lookups.
- Finally, the Persistence Layer ensures atomic page updates, durability, and crash recovery.
- Query results or acknowledgements propagate back upward to the client.
Storage and Persistence
UmaDB persists all data in a single paged file, using three specialized B+ trees each optimized for different access patterns.
Two header nodes act as the entry point for all data structures and track the current transaction sequence number (TSN), head position, and next never-allocated page ID.
UmaDB maintains three specialized B+ trees in the same paged file:
- Events Tree: Maps each event position (monotonically increasing sequence number) to an event record, optimized for sequential scans and range queries.
- Tags Tree: Maps each tag to a list of positions or per-tag subtrees, optimized for filtered queries by event tags
- Free Lists Tree: Maps each TSN (transaction sequence number) to a list of freed page IDs, enabling efficient space reclamation
Events Tree
The events tree is a position-ordered B+ tree that stores all events in UmaDB. Each event is assigned a unique, monotonically increasing Position (a 64-bit unsigned integer) when appended, which serves as the key in the tree.
- Keys: event position (64 bit integer)
- Values: event record (type, data, tags, and optionally overflow root page ID)
The events tree is the authoritative source for event data.
Events are stored using one of two strategies based on payload size:
- Small events: stored directly in the B+ tree leaf nodes
- Large events: stored in a chain of event data overflow pages
The overflow chain is a singly-linked list of pages.
The tree supports:
- Sequential appends
- Position lookups
- Range scans
The tags tree provides a secondary index into this tree but does not duplicate event payloads.
Tags Tree
The tags tree provides an index from tag values to event positions. This enables efficient queries for events matching specific tags or tag combinations, which is essential for filtering, subscriptions, and enforcing business-level constraints.
- Keys: Tag hash (a stable 64-bit hash of the tag string)
- Values: List of event positions or pointer to per-tag subtrees for high-volume tags
The tags tree is optimized for:
- Fast insertion of new tag-position pairs during event appends
- Efficient lookup of all positions for a given tag, even for tags with many associated events
- Space efficiency for both rare and popular tags
The tags tree is a core component of UmaDB's storage layer, enabling efficient tag-based indexing and querying of events. Its design supports both rare and high-frequency tags, with automatic migration to per-tag subtrees for scalability. The implementation is robust, supporting copy-on-write, MVCC, and efficient iteration for both reads and writes.
Free Lists Tree
The free lists tree provides an index from TSN to page IDs. This enables efficient selection of reusable page IDs, which is essential for efficient page reuse.
The free lists tree is a B+ tree where:
- Keys: TSN when pages were freed
- Values: List of freed Page IDs, or Page ID of per-TSN subtrees
The free lists tree is a core component of UmaDB's space management and page recycling strategy. Unlike the events tree and the tags tree, the free lists tree supports removal of page IDs and TSNs.
The free lists tree is also implemented with the same copy-on-write semantics as everything else. The freed page IDs from copied pages of the free lists tree are also stored in the free lists tree. The page IDs reused when writing pages of the free lists tree are also removed from the free lists tree. All of this is settled during each commit before the header node is written, ensuring the free list tree is also crash safe.
MVCC and Concurrency
UmaDB implements multi-version concurrency control (MVCC) using a copy-on-write strategy. Each transaction (read or write) operates on a consistent snapshot identified by the header with the highest TSN. Writers never mutate pages in place; instead, they allocate new pages and atomically update the alternate header to publish new roots.
When a writer modifies a page, it creates a new version rather than mutating the existing page in place. This ensures readers holding older TSNs can continue traversing the old page tree without blocking. Without page reuse, the database file would grow as each write creates new page versions, such that very quickly most of the database file would contain inaccessible and useless old versions of pages.
The free lists tree records which pages have been copied and rewritten so that they can be safely reused. Freed pages are stored in the free lists tree, indexed by the TSN at which they were freed. Pages can only be reused once no active reader holds a TSN less than or equal to the freeing TSN. When pages are reused, the page IDs are removed from the free lists tree. TSNs are removed when all freed page IDs have been reused. Writers first attempt to reuse freed pages, falling back to allocating new pages. The database file is only extended when there are no reusable page IDs. Batching read responses helps to ensure freed pages are quickly reused.
Key points:
- Readers: Traverse immutable page versions, never block writers.
- Writers: Allocate new pages, update B+ trees, and commit by atomically updating the header.
- Free Lists: Track reusable pages by TSN, enabling efficient space reclamation.
Implementation details:
- The database file is divided into fixed-size pages with two header pages storing metadata (TSN, next event position, page IDs).
- Readers register their TSN and traverse immutable page versions.
- Writers receive a new TSN, copy and update pages, then atomically update the header.
- Free lists track pages by TSN for safe reclamation.
- Readers use a file-backed memory map of the database file to read database pages.
- Writers use file I/O operations to write database pages for control on when pages are flushed and synced to disk.
This design combines non-blocking concurrency, atomic commits, and efficient space management, making UmaDB fast, safe, and consistent under load.
Transaction Sequence Number (TSN)
UmaDB uses a monotonically increasing Transaction Sequence Number (TSN) as the versioning mechanism for MVCC. Every committed write transaction increments the TSN, creating a new database snapshot.
The TSN is written into oldest header node at the end of each writer commit. Readers and writers read both header pages and select the one with the higher TSN as the "newest" header.
Reader Transactions
A reader transaction captures a consistent snapshot of the database at a specific TSN. Readers do not hold locks and never block writers or other readers.
Each reader holds:
- A transaction sequence number
- A snapshot of the B+ tree root page IDs
When a reader transaction starts, it adds its TSN to the register of reader TSNs. And then when a reader transaction ends, it removes its TSN from the register of reader TSNs. This enables the writers to determine which freed pages can be safely reused.
The register of reader TSNs allows writers to compute the minimum active reader TSN, which determines which freed pages can be reused. Pages freed from lower TSNs can be reused.
Writer Transactions
Only one writer can execute at a time. This is enforced by the writer lock mutex, but in practice there is no contention because there is only one append request handler thread.
A writer transaction takes a snapshot of the newest header, reads the reader TSN register, and finds all reusable page IDs from the free lists tree. It executes append requests by first evaluating an append condition to look for conflicting events. If no conflicting events are found, it appends new events by manipulating the B+ tree for events and tags.
UmaDB writers never modify pages in place. Instead, writers create new page versions, leaving old versions accessible to concurrent readers. When a writer needs to modify a page, it will:
- Allocate a new page ID (either from its reusable list of page IDs or by using a new database page)
- Clone the page content to the new PageID
- Add the new page to a map of dirty pages
- Add the old page ID to a list of freed page IDs
Once a page has been made "dirty" in this way, it may be modified several times by the same writer.
After all operations for appending new events have been completed, the reused page IDs are removed from free lists tree, and the freed page IDs are inserted. Because this may involve further reuse and freeing of page IDs, this process repeats until all freed page IDs have been inserted and all reused page IDs have been removed.
Then, all dirty pages are written to the database file, and the database file is flushed and synced to disk.
Then, the "oldest" header is overwritten with the writer's new TSN and the new page IDs of the B+ tree roots. The database file is then again flushed and synced to disk.
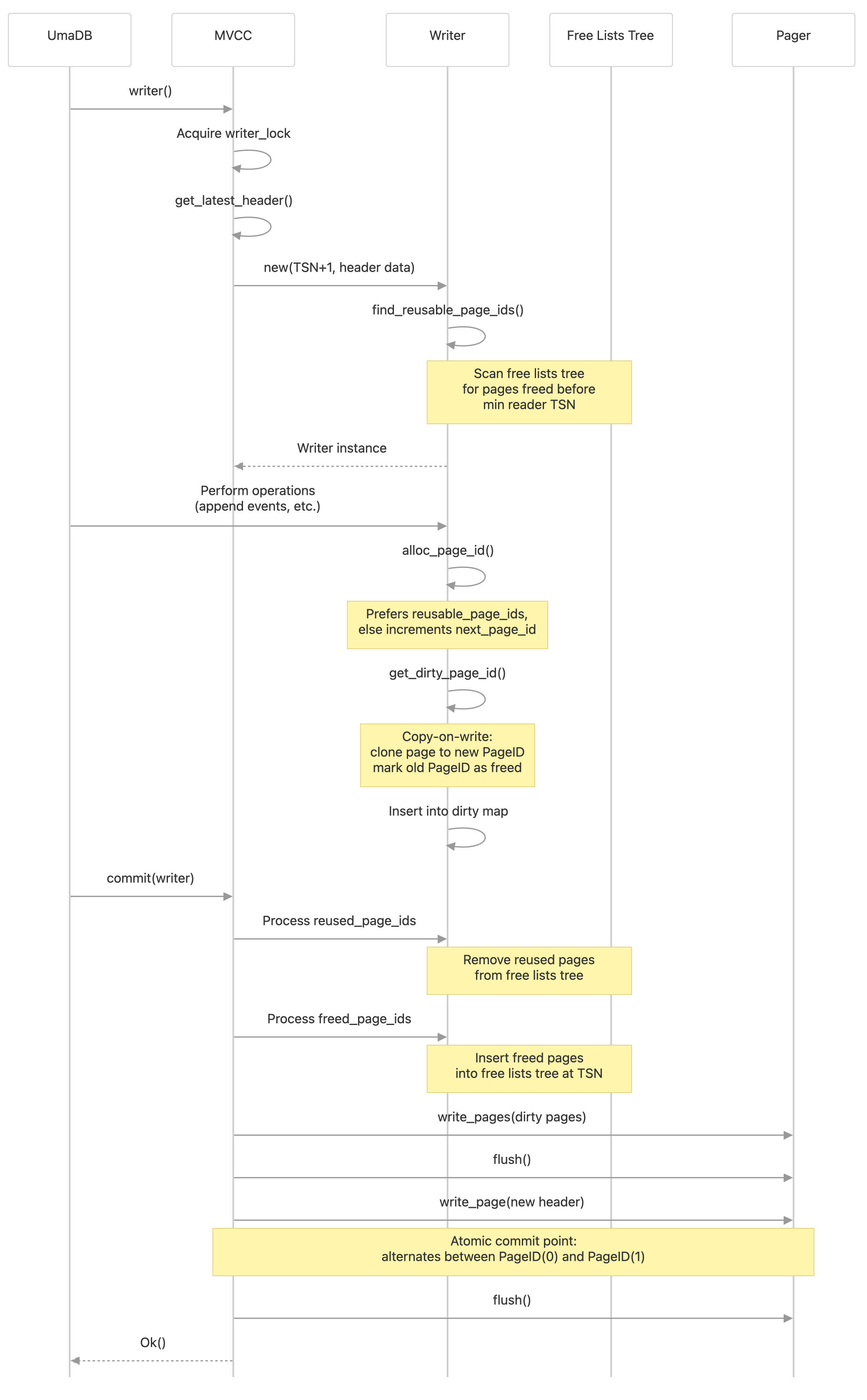
This design yields crash-safe commits, allows concurrent readers without blocking, and efficiently reuses space.